Googles Kampf gegen Scraper-Sites

Eine Scraper-Site ist eine Seite, die ein Großteil ihres Inhaltes automatisiert aus anderen Quellen klaut. In einem Tweet hat Matt Cutts nun darauf hingewiesen, dass Google solche schmutzigen Methoden nicht mag. Man solle sogar aktiv Beispiele von Scraper-Sites an Google melden. Soweit so gut. Der britische Online-Experte Dan Barker hat daraufhin ein erschreckendes Beispiel bei Twitter gepostet. Man sollte ihm dafür eine Medaille überreichen:

Matts Tweet: „Wenn man eine Scraper-URL sieht, die vor der Original-Quelle in den Suchergebnissen rankt, soll man das melden: …“ Hier die Antwort von Dan Barker:
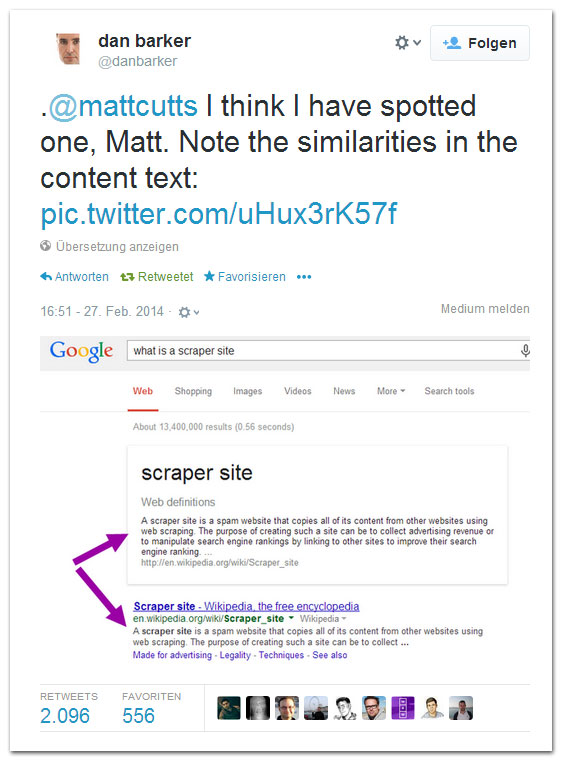
[Quelle] Die Suche nach „what is a scraper-site“ zeigt als erstes eine Knowledge-Graph Definition, die Google aus Wikipedia übernommen hat. Man kann sogar feststellen, dass der gesamte Knowledge-Graph automatisch aus gescrapten Texte generiert wird.
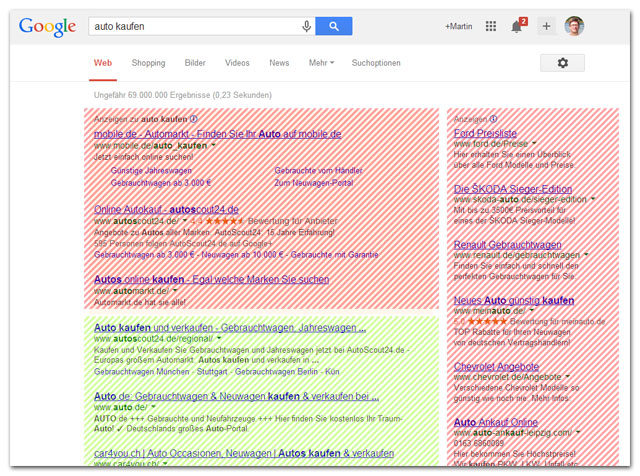
Das Beispiel zeigt sehr anschaulich, wie Google bei den geforderten (moralischen) Richtlinien mit zweierlei Maß misst. Während andere nicht mit solchen Techniken arbeiten dürfen, macht Google das selbstverständlich. Bei der berühmten „Werbung above the Fold“ (im sichtbaren Bereich) ist es genauso: Seit dem „Layout-Update“ werden Seiten, die zu viel Werbung im Kopfbereich haben, abgestraft. Aber natürlich gibt es zahlreiche Beispiele von Google-Seiten, auf denen die Werbung mehr als 60 – 70% des sichtbaren Bereiches einnimmt. Hier das Beispiel „Auto kaufen“ – jede andere Website würde bei so viel Werbung von Google abgestraft:
Was meint ihr? Ist es legitim, dass Google als wirtschaftlich orientierter Konzern solche Richtlinien vorgibt, ohne sich selber daran halten zu brauchen?
13 Kommentare zu „Googles Kampf gegen Scraper-Sites“
Hi,
also bzgl. deines ersten Beispiels ist noch unklar, ob es zwischen Google und Wikipedia eine Art „Vertrag“ gibt, denn ich könnte mir vorstellen, dass Google bei der jährlichen Spendenaktion schon mitwirkt, zumal dort auch der Link des Beitrages angegeben wird.
Zum zweiten Beispiel bin ich der Meinung, dass Google mit der Werbung in den Suchergebnissen übertreibt, denn im rechten Bereich halte ich Werbung für in Ordnung, jedoch Websites nur ganz oben anzuzeigen, wenn die Betreiber dafür bezahlen, halte ich für nicht in Ordnung und zerstört meiner Meinung nach auch den Gedanken an qualitativ hochwertigen Suchergebnissen und in den meisten Bereich wird SEO überflüssig, da Werbung pro Klick einfach unbezahlbar geworden ist.
Es ist quasi ein Eingriff in den Markt und sortiert alle Unternehmen/Websites aus, welche nicht das Geld haben 5 Euro pro Klick zu zahlen, aber sich trotzdem liebevoll um den Content und um die Seite kümmern.
VG
Yannic
Ob legitim oder nicht, spielt keine Rolle. Google ist in der Lage dazu und kann es sich erlauben. Und seit wann agiert Google in irgendeiner Weise moralisch? Google macht sich das Internet, wie es ihnen gefällt. Und Google und den Anlegern gefällt das Internet besonders gut, wenn der Rubel rollt.
Natürlich könnte man da manchmal an die Decke gehen, aber was bringt es. Wenn Google als Leittier mit seiner Glocke läutet, folgen die Schäfchen treudoof…
Die ganze Aufregerei über Google bringt nichts ohne Konkurrenz bzw. ist sinnlos, wenn hierzulande Google weiterhin über 90% Marktanteil hat.
Schönes Wochenende. ;-)
Jojo – „Alle Tiere sind gleich. Aber manche sind gleicher als die anderen.“ – die grossen Tiere eben ………..
Hi Martin,
sehr gerne lese ich deinen Blog und noch nie habe ich einen Kommentar dagelassen. [Das möchte ich nun ändern :) ]
Zum Thema Moral muss ich sagen, dass Google ein Konzern und google.de eben deren Unternehmensseite ist. Was Google damit macht, sollte eigentlich Ihnen überlassen bleiben. Es ist doch so, dass wir User schuld daran sind, dass sie so groß sind, wie sie es eben sind.
Das Google jetzt seiner Konkurrenz Platz geben muss (EU Urteil), kann ich nicht verstehen. Dann muss man auch Nike zwingen, dass man dem User Puma im Nike Store anbietet… Natürlich dient es am Ende dem Verbraucher. Aber der Verbraucher muss Google nicht nutzen und er kann seine Puma Schuhe auch wo anders holen.
Das Google was gegen diese nutzlosen Scraper machen möchte, finde ich persönlich erst mal sehr gut. Das Google aber den moralischen Zeigefinger hebt, finde ich doch sehr fragwürdig. Google verstößt ja in mehreren Dingen gegen seine eigenen Richtlinien. Sind wir aber wieder beim Thema Seitengestaltung. Google kann auf seiner Seite machen was es möchte und Google stellt die Regeln auf, wie man dort eben weit oben rankt.
Natürlich ist es nicht in Ordnung, dass Sie Werbung verbieten, allerdings geht es ja auch hierbei um den Mehrwert für den User. Seiten die nur Werbung haben und sonst keinen Nutzen, die haben auch keine Daseinsberechtigung und die möchte Google los werden. Wir Blogger dagegen bieten (meistens) einen Mehrwert und hier ist Werbung legitim, solange es eben nicht überhandnimmt.
Viele Grüße
Christian
Das zeigt doch mal wieder was sich die Übermacht Google erlauben darf, darf sich noch lange nicht jeder erlauben. Vielen Dank für diesen interessanten Artikel.
VG
Martin
Moin,
Bezüglich der Werbung hat Matt Cutts in einem seiner Videos mal gesagt, dass bei den meisten Suchanfragen auf Google keine Werbeanzeigen ausgeliefert werden. Deswegen sei die Anzahl und Position der Werbung in den Suchergebnissen völlig in Ordnung….
Den Link zum Video habe ich leider auf die schnelle nicht gefunden.
Das war nicht das Tor des Monats sondern der Tweet des Jahres, ich sage mal schon jetzt der ist nicht mehr zu toppen.
Ich verstehe die Aufregung nicht. Die „Web definitions“ und auch der „Knowledge Graph“ sind doch nur eine etwas andere Darstellungsformen von Suchergebnissen. Der erste, so hervorgehoben Treffer führt ja nicht zu Google, sondern weiterhin zur Wikipedia bzw. zur Quelle der Informationen.
Als vor gut einem Jahr die Sache mit der neuen Google-Bildersuche für Aufregung sorgte, gab es auch hier in den Kommentaren viel Unverständnis ob der Bedenken der Bilder-Urheber. Ist doch alles prima, das will der Suchende ja haben, nämlich die Bilder. Die Seiten selbst interessieren sowieso niemanden und so.
Ja und nun sind alle plötzlich empört über das böse Google. Was ist da jetzt der Unterschied? Ich finde es gut, wenn ich die relevanten Informationen direkt per „Web definitions“ und „Knowledge Graph“ angezeigt bekomme. Wozu soll ich da erst noch die Seite der Wikipedia besuchen?
@Schnurpsel: Also bitte, das ist ja wohl deutlich zu kurz gedacht.
Das Internet funktioniert deshalb, weil diejenigen die Inhalte erstellen durch Werbeeinnahmen etc das ganze finanzieren können.
Eignet sich Google z.B. die Bilder selbst an und zeigt sie auf den eigenen Seiten an, ist das nicht mehr möglich, ergo wird es dann irgendwann auch keine neuen Bilder mehr geben, weil es für die Ersteller nicht mehr lukrativ ist.
Und genau auf diese Art läuft es ja in vielerlei Hinsicht momentan im Internet, Google versucht sich alles selbst zu krallen, was schlussendlich dazu führen wird, dass die Vielfalt des Internet deutlich abnehmen wird.
Natürlich mag es für den User ohne Weitblick praktischer sein, die Bilder, Infos etc direkt bei Google finden zu können und nicht auf eine externe Webseite gehen zu müssen. Langfristig schadet es aber dem Internet.
Und wenn Du die „Aufregung“ um den Tweet nicht verstehst, kann ich Dir da dann auch nicht weiter helfen. Dabei ist das doch ganz einfach zu verstehen: Google findet Scraping blöd (isses ja auch in der Tat), ist aber selbst der größte Scraper von allen. Das ist der Gag an der gezeigten Twitter-Konversation und ein schönes Beispiel von vielen, wie Google für sich selbst andere Maßstäbe ansetzt als für andere.
@Daniel
Hast Du Dir mal den Artikel zu den Scraper-Sites in der Wikipedia durchgelesen? Der Link aus den „Web definitions“ führt ja genau dort hin, und nicht etwa zu einer Google-Seite mit dem vollständigen Artikel.
Klar, die Google-Suchergebnisseiten bestehen praktisch nur aus fremden, zusammengesammelten Inhalten. Sie ranken aber nicht bei Google und auch nicht bei anderen Suchmaschinen.
Aber gut, Google könnte natürlich als Suchergebnis nur den Link anbieten, ohne Titel, Snippet und sonstigen Informationen. :-)
Mein Bezug zu den Änderungen in der Bildersuche sollte nur andeuten, wie manche mit zweierlei Maßstab messen. Vor gut einem Jahr gab es eben auch viele Stimmen, die das alles prima fanden und jetzt, wo es nicht nur um die Bilder geht, plötzlich über Google herziehen.
Gut finde ich das übrigens auch nicht, was Google da mit den Bildern macht. Bei mir kommen ca. 90% der Besucher von der Bildersuche und ich kann von Glück sagen, daß es die neue Bildersuche noch immer nicht in DE gibt.
Wie bereits in den anderen Kommentaren teilweise gesagt, kann sich Google in dieser Hinsicht (fast) alles erlauben. Es ist allerdings eine Fehleinschätzung, wenn man annimmt, dass Google primär wirtschaftliche Interessen verfolgt: Google weiss ganz genau, das es solange seine Monopolstellung halten wird, wie es dem User die beste Benutzererfahrung garantieren kann. Dies ist das oberste Ziel, erst danach wird hieraus versucht seinen Gewinn zu maximieren – das sieht man beispielsweise auch anhand von Adwords, wo Anzeigen, die ein niedrigeren Preis jedoch die bessere Nutzererfahrung haben, vor Anzeigen geschaltet werden, an denen Google zwar mehr verdient, wo aber die Userexperience schlechter ist.
Die Kommentare sind geschlossen.