Google Rankingfaktoren, Algorithmus, Rank-Brain und das ganze Zeugs …
Zur Zeit steht das Thema „Google Rankingfaktoren“ wieder hoch im Seo-Diskurs. Es laufen kontroverse Debatten, welcher Faktor wie viel Einfluss hat – oder ob das Thema tot sei. Hier mein Beitrag dazu :-) Natürlich sind die Signale, die Google ermitteln kann und die als Rankingfaktoren in den Algorithmus einfließen, nach wie vor die entscheidende Grundlage. Was in der ganzen Diskussion jedoch fehlt und oft zu Missverständnissen führt, ist ein Modell, wie diese Faktoren denn überhaupt verarbeitet werden. Was ist eigentlich der „Google Index“? Was ist im Google-Index das primäre Ordnungskriterium? Und wie genau funktioniert dieser „Google-Ranking-Algorithmus“?
Das Ganze ist leider etwas komplexer und länger, und ich habe überlegt, da ein E-Book draus zu machen – aber hey: ein Bilder-SEO-E-Book reicht. Und genau genommen habe ich das Folgende nur aufgrund des Bilder-Ebooks entwickeln können. Auch hier, wie so oft, der Hinweis: es handelt sich um ein Modell, das ich entwickelt habe. Kann sein, dass alles anders ist. Letztlich sind es Formeln, und da man die so schlecht lesen kann, versuche ich sie in Worte zu übersetzen, was natürlich Unschärfen nach sich zieht.
Was ist der Google-Index?
Warum kann Google in Sekunden-Bruchteilen Suchergebnisse präsentieren. Es gibt Milliarden von Websites, die können unmöglich in Sekundenschnelle komplett miteinander verglichen werden. Das heißt: die Rankings für einzelne Suchanfragen sind im Grunde schon vorher berechnet. Stellt sich also die Frage: wie genau ist der Google-Index aufgebaut. Was ist das vorrangige Ordnungskriterium? Besteht der Google-Index aus URLs, denen jeweils relevante Keywords zugeordnet sind?
Nein, das würde keinen Sinn ergeben: denn es gibt viel mehr Websites (URLs) als Begriffe. Die deutschen Sprache umfasst rund 500.000 Begriffe. Dem gegenüber stehen Milliarden von deutschsprachigen Websites. Es ist also folgerichtig, dass der Google-Index auf rund 500.000 Einträgen basiert. (Das ist natürlich zu kurz gedacht. Aber zunächst soll es der Einfachheit halber nur um Begriffe gehen, auch wenn es sich letztlich um „Terme“ handelt“, also auch um Wortfolgen).
Soweit so gut.
Was passiert bei der Indexierung?
Zäumen wir das Pferd nun von der anderen Seite auf: Nehmen wir eine beliebige Website. Damit sie in den Google-Index gelangen kann, muss sie von einem Crawler erfasst werden. Ein Crawler ist letztlich nichts anderes als ein kleines Computer-Programm, dass eine URL aufruft und den Inhalt herunterlädt. Zum Thema Crawling gehören Stichworte wie Crawling-Budget und Sitemap.
Google hat also den Quellcode einer Website heruntergeladen und beginnt nun mit der Analyse der Seite. Dafür wird zunächst in zwei Bereiche getrennt:
- die URL – und alles was dazu gehört (Offpage)
- der Seiteninhalt – und alles was dazugehört (Onpage)
In beiden Bereichen arbeiten völlig verschiedene Algorithmen, und zwar weitgehend unabhängig voneinander. Die Ergebnisse werden später wieder zusammengeführt, dazu unten mehr.
Der Onpage-Algorithmus
Mit Hilfe eines Algorithmus wird die inhaltliche Relevanz einer Website errechnet. Bei dieser Relevanz-Berechnung spielen die altbekannten Rankingfaktoren wie Seitentitel, Zwischenüberschriften, Bilder, Videos, ausgehende Links etc. eine wichtige Rolle. All diese Daten lassen sich aus dem Quellcode ziehen, und jeder Faktor kann im Verhältnis zu den anderen unterschiedlich gewichtet werden. Zum Beispiel ist die erste Überschrift wichtiger als der Seitentitel und eine Zwischenüberschrift ist höher gewichtet als ein Text am Ende der Seite. All diese Berechnungen lassen sich tatsächlich in einer Formel ausdrücken. Aber was genau wird eigentlich berechnet? Der „Inhalt an sich“???
Nein, es werden einzelne Terme durchgerechnet, und zwar im Prinzip jeder Term, der auf einer Seite auftaucht. Das kann ein einzelner Begriff sein, aber auch mehrere Begriffe hintereinander (z.B. „Schuhe“ oder „Schuhe putzen“). Am Ende der Relevanz-Berechnung steht eine Liste mit Termen, für die diese Seite Relevanz besitzt. In dieser ersten Phase reicht es, wenn der Term einfach nur häufig auf der Seite vorkommt. Die eigentliche, differenzierte Berechnung findet erst später statt. Hier mus nur geklärt werden, was später überhaupt berechnet werden soll.
- Am Ende werden die relevantesten Terme auf ToDo-Listen gesetzt – inkl. der URL, für die diese Werte berechnet wurden.
- Alle URLs. die in dem Dokument als Links gefunden wurden, werden auf eine (Offpage-)ToDo-Liste gesetzt.
- Zudem werden alle Bild-URLs auf eine ToDo-Liste gesetzt (was dann genau geschieht, habe ich sehr detailliert in meinem Bilder-Seo-E-Book beschrieben).
Die ToDo-Listen bei der Indexierung
Es gibt im Google-Backend eine ganze Reihe von ToDo-Listen. Das Prinzip dahinter: Für verschiedene Berechnungsprozesse steht jeweils ein Heer von spezialisierten Algorithmen/Programmen zur Verfügung. Innerhalb eines Bereiches machen alle das gleiche: sie arbeiten das ab, was ihnen jeweils auf die ToDo-Liste gesetzt wurde. Wenn also ein Onpage-Algorithmus die Terme einer Website neu berechnet hat, dann landen diese Terme auf einer Liste, die dann zu einem späteren Zeitpunkt von einem anderen Algorithmus aufgegriffen und verarbeitet werden.
Das Prinzip der ToDo-Liste ist für das Verständnis des Google-Backends fundamental!
Der Offpage-Algorithmus
Parallel zur Onpage-Analyse wird eine Offpage-Datenbank gepflegt: hier werden URL gesammelt sowie alle Signale, die eine URL betreffen. Das sind im Wesentlichen Backlinks aus interner und externe Verlinkung. Auch Social-Media-Signale sind letztlich nichts anderes als Links. All diese Links werden dann in einem separaten Algorithmus gewichtet. In diesem Bereich spielt auch der berühmte Google-Pagerank eine Rolle. Bei der Link-Analyse sind unter anderem folgende Faktoren wichtig:
- Ankertext
- die Position des Links im Inhalt
- follow oder nofollow
- PageRank der Linkquelle
- Trust der Linkquelle (wird aus einer anderen Datenbank gezogen, siehe unten)
- Autorität der Linkquelle (wird aus einer anderen Datenbank gezogen, siehe unten)
- Brand-Wert der Linkquelle (wird aus einer anderen Datenbank gezogen, siehe unten)
- SSL / https
- Klickrate (?) – unklar, weil Google leugnet, Daten aus Analytics oder Chrome zu verwenden
Am Ende der Berechnung hat jede URL verschiedene Score-Werte. Dazu gehört neben dem PageRank auch der Trust, die Autorität und ein Brand-Bonus.
Auch hier wird die neu berechnete URL auf eine ToDo-Liste gesetzt, damit die neuen Werte von anderen Algorithmen später weiterverarbeitet werden.
Zwischenstand …
Eine Website wurde also geteilt in URL und Inhalt, und beides wurde analysiert.
- Ergebnis der Onpage-Berechnung ist eine Liste mit relevanten Termen (Keywords).
- Ergebnis der Offpage-Berechnung ist ein neuer URL-Score-Wert, der die Gewichtung der eingehenden Links anzeigt.
Das reicht aber noch nicht als Grundlage für den eigentlichen Ranking-Algorithmus …
Autorität, Trust und Brand
Natürlich spielen auch übergeordnete Website-Faktoren eine wichtige Rolle. Das sind die Faktoren, die eine Domain insgesamt betreffen. Dazu gehören zum Beispiel die Anzahl der Seiten einer Domain, die Gesamtanzahl und die Qualität aller eingehenden Links, die Anzahl der Domain-Name-Erwähnungen und vieles mehr. Diese übergeordneten Faktoren sind weitgehend „unerforscht“. Sie geistern als „Aurtorität“, „Trust“ und „Brand“ durch die SEO-Gedankenspiele. Klar ist: sie haben ein großes Gewicht. Unklar ist, wie sie sich letztlich genau berechnen.
In diesem Artikel soll es aber nur um den Ablauf an sich gehen, daher nur so viel:
Ein dritter, übergeordneter und zeitlich nachgeschalteter Algorithmus kombiniert die zuvor berechneten Ergebnisse und berechnet daraus übergeordnete Werte, die in eine Domain-spezifische Datenbank eingetragen werden.
Diese Datenbank enthält für jede Domain jeweils spezifische Score-Werte:
- Trust (Qualität der eingehenden Links)
- Autorität (Qualität der kulmulierten Inhalte aller Unterseiten einer Domain, Anzahl der Bilder und Medien, Ankertexte etc.)
- Brand-Score (Anzahl der Erwähnungen, Social-Media-Signale, Direkt-Type-Ins, etc.)
Diese Domain-Datenbank wird vermutlich nur parallel gepflegt. Veränderungen werden nicht auf eine ToDo-Liste gesetzt, sondern wirken sich erst aus, wenn ein anderer Teil-Algorithmus auf diese Daten zugreift. Allerdings werden die Werte vermutlich bei jeder Neuberachnung hinzugezogen.
Der Core – das Herzstück des Google Backends
Alles bisherige waren nur vorbereitende Berechnungen. Erst jetzt fließen die Daten wirklich zusammen. Und erst jetzt kommt das, was man gemeinhin als „Google-Index“ bezeichnet. Wie eingangs erwähnt, handelt es sich dabei um eine Datenbank, die Terme enthält, z.B. „Schuhe“, „Schuhe putzen“, „Welche Farben hat der Regenbogen“, „Warum bin ich doof“ und so weiter. Durch die Kombinationsmöglichkeiten ergibt sich wahrscheinlich eine Größe von rund 50 – 100 Mio Einträgen. Letztlich spielt die Größe aber keine Rolle (dazu unten mehr).
Entscheidend ist, dass der Google-Index nicht nach URLs sortiert ist, sondern auf Basis von Termen.
Ein wiederum sehr spezieller Algorithmus, der vollkommen anders als die zuvor genannten funktioniert, pflegt nun diesen Index. Die dahinter liegende Datenbank besteht im Wesentlichen aus zwei Bereichen:
- Informationen zu dem Term.
- Einer Liste von URLs, die für diesen Term Relevanz haben.
Zu den Informationen gehören zum Beispiel Synonyme, die Anzahl der Anfragen, die Anzahl der Bilder zu diesem Term, die durchschnittliche Verweildauer (?), ergänzende Suchbegriffe (wenn User den Term in der Anfrage verfeinern) und vieles mehr. Aus diesen Daten kann Google zum Beispiel errechnen, wann eine Universal-Search Integration angezeigt werden soll, welche Begriffe als Suchvorschläge angeboten werden, etc.
Jeder Term enthält eine Reihe von URLs, die erst hier, im Google-Core, berechnet werden. Dazu werden die zuvor berechneten Daten, also …
- der jeweilge Score-Wert aus der Onpage-Berechnung und
- die Score-Werte aus der Offpage-Berechnung
miteinander kombiniert. Als Ergebnis erhält die URL für das Ranking innerhalb dieses Terms einen bestimmten „Term-Score-Wert“. So wird also für jeden Term – oder anders gesagt: für jedes Keyword – schon vorab ein Ranking berechnet.
Aus dem zuvor Beschriebenen sind zwei ToDo-Listen hervorgegangen, die abgearbeitet werden. Jeder Term hat eine ToDo-Liste, und im Prinzip gibt es für jeden Term mindestenes einen Algorithmus, der diese Liste abarbeitet. Auf der Liste steht jeweils eine URL, und der Algorithmus berechnet die Rankingposition (für diesen Term und die jeweils genannte Website) neu.
Um die Geschwindigkeit der Ergebnis-Auslieferung zu maximieren, werden auch schon für jede URL die Snippets berechnet und angelegt. Dabei kann es zu Abweichungen kommen (Seitentitel, Description). Die Snippet-Berechnung ist ebenfalls Term-spezifisch.
Es sind also Millionen von kleinst-Programmen, die in Sekundenbruchteilen jeweils unabhängig voneinander arbeiten und den Google-Index so gut wie möglich auf dem neuesten Stand halten. Alle bekannten Verzögerungen, die man als Webmaster beobachtet, basieren darauf, dass die eigene Website auf irgendeiner ToDo-Liste steht und abgearbeitet werden muss.
Rank-Brain
Dieser Core-Algorithmus ist seit einiger Zeit schlau. Lange Zeit basierten die Berechnungen auf vorgegebenen Gewichtungen, z.B. Onpage-Score=35%, Autorität=25%, Backlinks=20%, Trust=10%, Brand=10%.
Das ist nun nicht mehr so! Stattdessen funktioniert der Core-Algorithmus mit Hilfe von Variablen, die sich für jeden Term individuell ergeben. Die Datenbank enthält also für jeden Term die Gewichtung der Rankingsignal für diesen Term. Die Gewichtung der einzelnen Rankingssignale wiederum wird aus User-Signalen gewonnen (soweit möglich) und aus AB- Tests, die Google permanent im Ranking durchführt. Aus der Masse der Signal lässt sich relativ gut herleiten, bei welchem Term die Benutzer welche Rankingsingale bevorzugen. Mal sind es viele Bilder, mal ist es eher eine SSL-Verschlüsselte Seite, mal sind es lange Texte und mal kurze Texte.
Rank-Brain bzw. die „künstliche Intelligenz“ dahinter ist letztlich nichts anderes, als das der Algorithmus sich selber die Variablen zusammensucht, die für jeden einzelnen Term relevant sind.
Und nun kommen wir wieder zum Anfang zurück: was passiert, wenn jemand eine Suchanfrage in das Google-Suchfeld eintippt? Dann wird im Index genau der entsprechende Datensatz aufgemacht.
Zunächst wird kontrolliert, ob ein Knowledge-Graph ausgespielt werden sollte oder ob Bilder, Videos, News. etc. von Bedeutung sind und an welche Stelle eine Onebox eingeblendet werden soll. Und dann wird das zu dem Zeitpunkt aktuelle, vorberechnete Ranking dieses Terms zurückgegeben (bzw. Pos. 1-10).
Aber was, wenn der Term noch gar nicht in der Google-Datenbank vorhanden ist?
Für dieses Szenario gibt es drei Möglichkeiten:
- Wenn mehrere Begriffe kombiniert wurden, die es so noch nicht als Anfrage gab: In dem Fall kombiniert Google die Einzel-Terme und sucht nach URLs, die in beiden Ranking-Listen auftauchen (hier ein Matt-Cutts-Video aus dem Jahr 2012, in dem er erklärt, wie das damals ablief).
- Wenn es sich um ein Kunstwort handelt, versucht Google Bestandteile zu extrahieren, die ein Term sein könnten.
- Wenn das nicht gelingt, wird kein Ergebnis angezeigt.
Infografik: die Google-Algorithmen
Hie rnoch mal die Zusammenhänge in einer Infografik. Ich denke, damit wird vieles klarer :-)
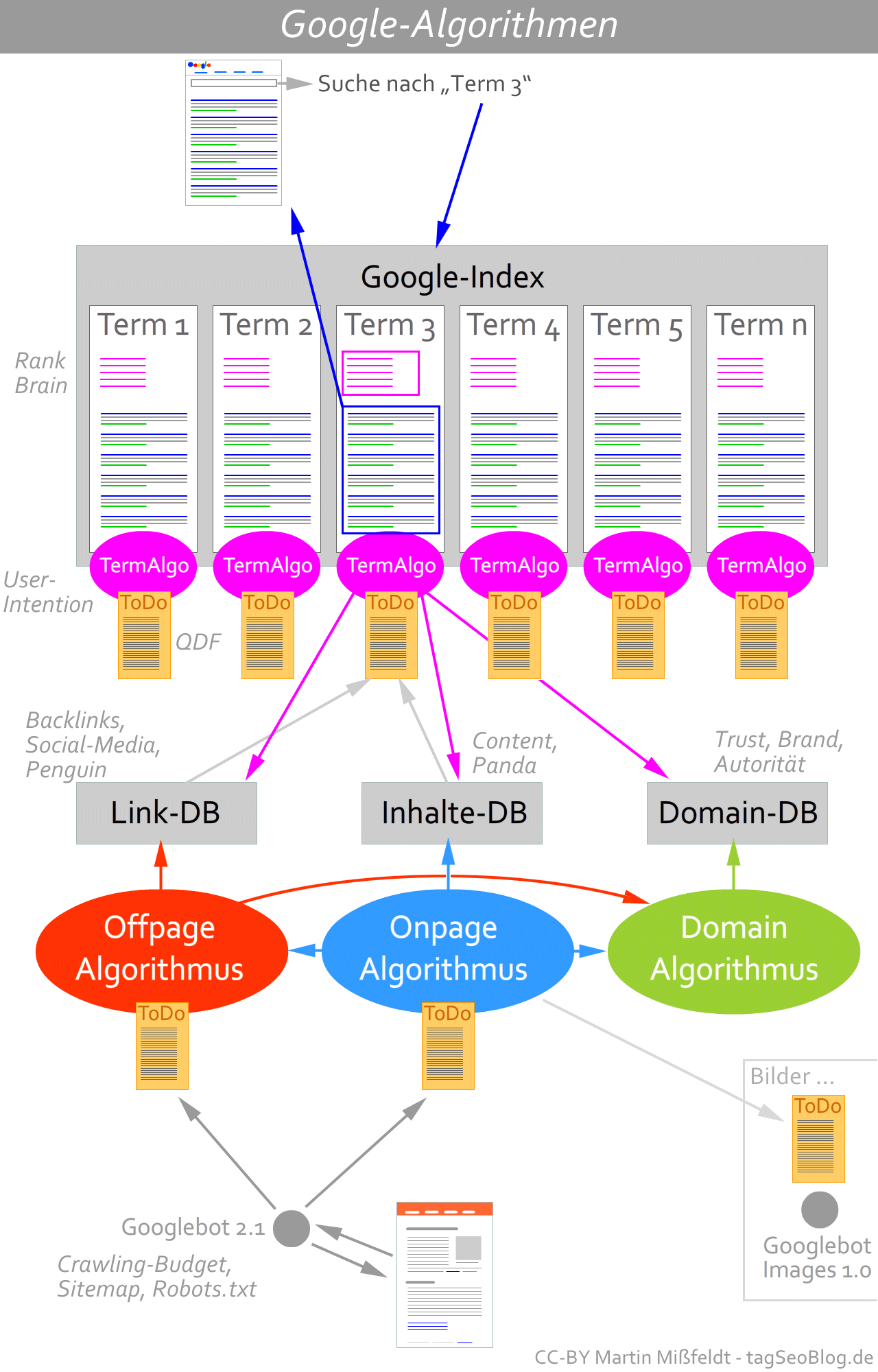
Zum Vergrößern bitte anklicken, darf man runterladen, ausdrucken etc. (CC-BY-Lizenz)
Was passiert bei QDF?
Nun gibt es Suchanfragen, die kurzfristig eine sehr hohe Relevanz bekommen (z.B. politische Ereignisse). Das lässt sich an den ToDo-Listen ablesen. Denn wenn eine ToDo-Liste für einen bestimmten Term in kurzer Zeit rasant anwächst (weil der Crawler entsprechend viele neue Seiten gefunden hat und sie dann nach einer Vorab-Berechnung auf der Term-To-Do-Liste gelandet sind), dann ist das ein eindeutiges Signal, dass dieser Term gerade sehr relevant ist. Dann kann der Core-Algorithmus wiederum schnell die Gewichtung der Ergebnisseite für diesen Term umstellen und zum Beispiel die News-Onebox aktivieren, ebenso die Bilder. Zudem kann kurzfristig das Signal „indexierungsdatum“ eine hohe Gewichtung bekommen. In Nullkommanix sind die Term-spezifischen Variablem umgestellt – und der Algorithmus stellt das vorberechnete Ranking entsprechend um.
Fazit: kein Hexenwerk, aber kurz davor
Das Ganze basiert natürlich auf Signalen, die Google als Rankingfaktoren nutzt. Zwei Dinge machen es so komplex und kompliziert:
- Mehrere parallele Algorithmen, die unabhängig voneinander arbeiten und ganz spezifisch funktionieren.
- Ein übergeordneter Algorithmus, der die Gewichtung seiner eigenen Faktoren jeweils selber festlegt.
Die Theorie, dass der Google-Algorithmus einfach nur eine sehr lange Formel ist, in die über 200 Faktoren einfließen, ist leider nicht mehr tragfähig.
Wenn man also über Rankingfaktoren sinniert, dann sollte man sich stets überlegen, an welcher Stelle im Google-Backend er denn greift und ob man überhaupt noch verallgemeinerbare aussagen treffen kann.
Der Artikel ist hochgradig spekulativ. Es handelt sich um ein erdachtes Modell, das lediglich auf Beobachtungen und Erfahrung basiert. Für meine Zwecke ist es gut geeignet, um Veränderungen erklärbar und plausibel zu machen. Aber natürlich muss jeder selber überlegen, inwieweit diese Überlegungen in das eigene Modell passen.
Und jetzt ihr! Plausibel? An welchen Stellen ist es unverständlich oder passt nicht zusammen?
Update: Vortrag von Paul Haahr
Danke an Olaf Kopp. Dank seines Hinweises habe ich diese Folien eines Vortrags des Googlers Paul Haahr gefunden, die ich gerne hier einbinde…
19 Kommentare zu „Google Rankingfaktoren, Algorithmus, Rank-Brain und das ganze Zeugs …“
Was für ein Wahnsinn! Dennoch ein großes Danke für die Zusammenfassung. Gut, das der Winter mit langen Abenden bevorsteht. Ich werde wohl noch einige Male lesen müssen. ;-)
Frank
Oh, ok. Hmm, vielleicht habe ich es doch zu kompliziert formuliert. Wenn man das alles schon seit langem so im Kopf verinnerlicht hat, geht man allzu leicht davon aus, dass alle das ja schnell und einfach so verstehen müssten.
Letztlich ist, glaube ich, wichtig, dass man sich ein eigenes Modell bastelt, mit dem man die eigenen Beobachtungen gut erklären kann. Und wenn etwas nicht erklärbar ist, muss man das Modell eben umdenken …
Ich glaube, mit „lange Winterabende;noch einige male lesen“ meinte Frank nur, das er, zwecks komplexerem Verständnis, seine eigenen, dafür angelegten Algorithmen (im Kopf), mit Deinen Thesen abgleichen muss. Geht mir ähnlich, und gelegentlich klickern dann immer mal wieder „Aha“-Erlebnisse. so hat man dann über den Winter etwas von Deinem Artikel..
*Daumen hoch*
Das ganze wird noch komplexer. Ich habe gelesen (finde die Quelle leider nicht) dass knapp 40% aller täglichen Suchanfragen so noch nie gestellt worden sind. Da wird das vorberechnen der Therme recht schwer. Dies bedeutet die Anfrage muss auch ein neurales Netz durchlaufen um „Keywords“ zu ermitteln.
Leicht zu sehen zum Beispiel an der Suche: „Diese frage wurde noch nie bei google gestellt“. Google skippt einfach sich selbst bei den Ergebnissen.
Ja, stimmt. Danke für den Hinweis. Das gehört alles in den ganz oberen Teil der Infografik, den ich gar nicht ausgearbeitet habe: wie interpretiert Google die Suchanfrage und auf welche Weise wird die Intention ermittelt.
Es ist schon Wahnsinn, dass das alles in so kurzer Zeit passiert …
Lieber Martin, schöne Zusammenfassung. Allerdings glaube ich schon, dass das Nutzerverhalten (=mehr als nur Klickrate in den SERPs) starken Einfluss auf die Bewertung der Qualität der Zielseite (in Bezug auf gewisse Suchintentionen) hat. Es kommt nicht von ungefähr, dass Google von den Webmastern in den eigenen Richtlinien jene Tipps zur Content-Erstellung forciert, die im Journalismus schon seit Jahrzehnten gelehrt werden (ob sie immer gut umgesetzt werden ist eine andere Geschichte…).
Auch einige Onpage-Faktoren sind darauf ausgerichtet, der Art und Weise, wie wir Medien konsumieren zu entsprechen. Das Medienverhalten hat sich nur durch das Medium geändert, aber kaum, wie wir die Information wahrnehmen. Du beweist das jedes Mal auf deinen Seiten, wenn du z.B. in der am besten zu sehenden Überschrift, dem Nutzer signalisierst, dass er hier die Information erwarten kann, die er gesucht hat (sollte ja die h1 sein) und er deswegen weiter liest.
Das Tracking und das Zusammenführen für die Interpretation dieser Daten funktioniert heute im Netz einfach nur deutlich einfacher. Früher waren sündteure Eyetracking-Studien von Unis notwendig. Heute können wir als Webmaster Nutzerverhalten selbst überwachen und interpretieren (wenn man technisch und analytisch dazu in der Lage ist). Unser Medienverhalten wurde von Google (mMn durch die Interpretation vieler Nutzerdaten) nur auf dieses Medium umgelegt. Und daher geben Sie diese Empfehlungen, die denen vergangener Jahrzehnte schon entsprechen. Allerdings glaube ich nicht, dass Google sich dabei auf fremdes Datenmaterial verlassen hat, sondern hier schon auf das eigene zurückgegriffen hat. Schon allein aufgrund der Tatsache, dass es sich um ein anderes Medium handelte und man nicht 100% wissen konnte, ob gewisse Dinge gleich ablaufen wie z.B. im Printbereich. Das zeigt sich bei einigen Suchintentionen in Verbindung mit Suchbegriffen ganz deutlich. Vor allem dann, wenn viele darauf optimierte Seiten kaum eine Chance haben zu ranken, weil sie der Suchintention dazu einfach nicht entsprechen. Gerne dazu in PNs mehr und auch einen Case, den ich dazu immer gerne zeige.
Beispielhaft sind dazu oft Fälle, wo Dienstleistungsbeschreibungen mit Jobangeboten in Konkurrenz stehen, und die Suchintention anhand der SERPs bereits deutlich zu erkennen ist. Geht man dem dann noch mit einem angepassten Dokument auf die Spur, lässt sich diese Interpretation der SERP-Daten auch meist (bei mir bislang immer) mit den dadurch generierten Anfragenintentionen bestätigen. Man kann man hier optimieren, was man will, mittel- bzw. langfristig werden die Nutzerdaten durch die Intention sich durchsetzen. Dass Nutzerdaten nicht alles sind, da sie leicht manipulierbar sind, ist Google (und uns) natürlich bewusst. Allerdings glaube ich, dass diese auch berücksichtig werden (selbst dann, wenn es nur intentionsspezifisch unterschiedlich gewichtet ist).
LG Manuel
wow, Danke Manuel. Ich staune immer wieder, wie umfangreich hier manche kommentieren – das ist nicht nur für mich gut, sondern auch alle weiteren Leser. Daher: danke.
Ja, das Nutzerverhalten hat mit Sicherheit einen zunehmend wichtigen Einfluss. Die Frage ist nur – und da gehe ich im Artikel aus Platzgründen nicht drauf ein – wie macht Google das genau? Letztlich müssen es ja Signale sein, die Google auswertet. Mit Analytics und Chrome, aber wohl auch mit Adsense, hätte Google drei Quellen, aus denen man sehr viele und sehr relevante Informationen extrahieren könnte. Einzig: Google bestreitet das – was aber natürlich nicht heißt, das sie es nicht machen. „Don’t be evil“ war vorgestern…
Interessante Diskussion hier mal wieder!^^
Ich bin auch treuer Anhänger der „User Signals“ Fraktion. Das ist eigentlich, mal abgesehen von der journalistischen Herkunft, mein Hauptgrund eigentlich seit ich „mit dem ganzen Ding“ angefangen habe „User! User! User!“ zu predigen. Und technische Spielereien/Tricks immer nur als temporären Vorsprung.
Auch wenn das jetzt noch kein so gewichtiger Faktor ist, bin ich mir sehr sicher, dass es langfristig DER Faktor, wenn nicht sogar der einzige relevante Faktor werden wird. Einfach weil man, in der Endkonsequenz in Kombination aller Medien („Suchschlitz“, Voice, Lens, usw.) den WAHREN User nur schwer faken kann. Alle anderen, vor allem: klassischen, Signale schon. Kein Wunder legt Google Wert auf massive Fortentwicklung der KI (Erkennung) / Blockchain (Verifikation) / Technik (für die Steuer) generell. Dass Google in den hier entscheidenden Bereichen mehr und mehr zum Gatekeeper auf verschiedenen Ebenen (Desktop/Mobile/Smartwear/Home/usw.) wird oder sein möchte…
Nur so: Wer ab und zu mal ein Script (zur Useremulation) ankauft hat sicher auch schon gemerkt, dass die (Guten) immer komplexer werden und es nicht mehr mit einer einfachen Änderung der Variablen getan ist. Selbst (geile) PBNs muss man heute teilweise schon so gut betreuen und pushen… dass es eigentlich mit den „alten“ easymode PBNs/Linkwheels (am besten noch auf Autopilot^^ ) usw. nicht mehr vergleichbar ist.
Hi Martin, vielen Dank für deine Antwort. Ich glaube, ich werde deine Grafik bei Beratungen das ein oder andere Mal als Beispiel nutzen (natürlich mit Urheber-Angabe und direkt auf deiner Seite). Sie ist sehr anschaulich. Zu dem Datenmaterial: Das sehe ich genauso. Es ist viel vorhanden. Die SERPs werden fast täglich besser. Die Daten, die wir daraus ableiten können, damit auch. Google bestreitet, aber hat auch schon öfters „zurückgerudert“ in den vergangenen Jahren. Man muss ja bei G auch immer zwischen den Zeilen lesen, was genau bestritten wird. Ohne der Aluhut-Fraktion zugeschrieben zu werden, glaube ich, dass sie jedenfalls irgendeinen Datenpool verwenden, der sehr valide ist, was Nutzerdaten angeht. Ob dafür all unsere G-Tool-Daten zusammengeführt werden, ist vermutlich wirklich nicht der Fall. Wir werden sehen. LG Manuel
Hi ,
danke für den hochinformativen Artikel!
Die Informationen sind kompakt, verständlich und kurzweilig aufbereitet und auch noch super verknüpft.Es ist sehr interessant zu lesen.
Grüße
Ist doch am besten so viel wie möglich wertvolle Inhalte zu schreiben und veröffentlichen? Der Algorithm verändert sich so oft, es wird immer schwiriger das alles zu verfolgen.
Hey Martin,
vielen Dank für die ausführliche Erklärung und das Video. Super-interessantes Thema, aber am Ende weiß wohl nur einer, wie es wirklich ist: Google selbst. Ich denke, mit gesundem Menschenverstand kommt man schon recht weit. Google möchte, dass wir auf unserer Suche das bestmögliche Ergebnis erzielen. Deshalb gilt für mich die einfach Wahrheit, immer an die Leser zu denken und ihre Fragen optimal zu beantworten.
Sehr hilfreiche und vollständige Information, kann vielen Nutzern helfen, werde den Blog auf jeden Fall weiter verfolgen.
Grüße aus Wien,
Martina
Die Kommentare sind geschlossen.